Search 9 million+
mathematical theorems
Describe a result in natural language, and TheoremSearch finds it across arXiv, the Stacks Project, and more. 70% more accurate than LLM search.
Luke Alexander, Eric Leonen, Sophie Szeto, Artemii Remizov, Ignacio Tejeda, Jarod Alper, Giovanni Inchiostro, Vasily Ilin
Motivation
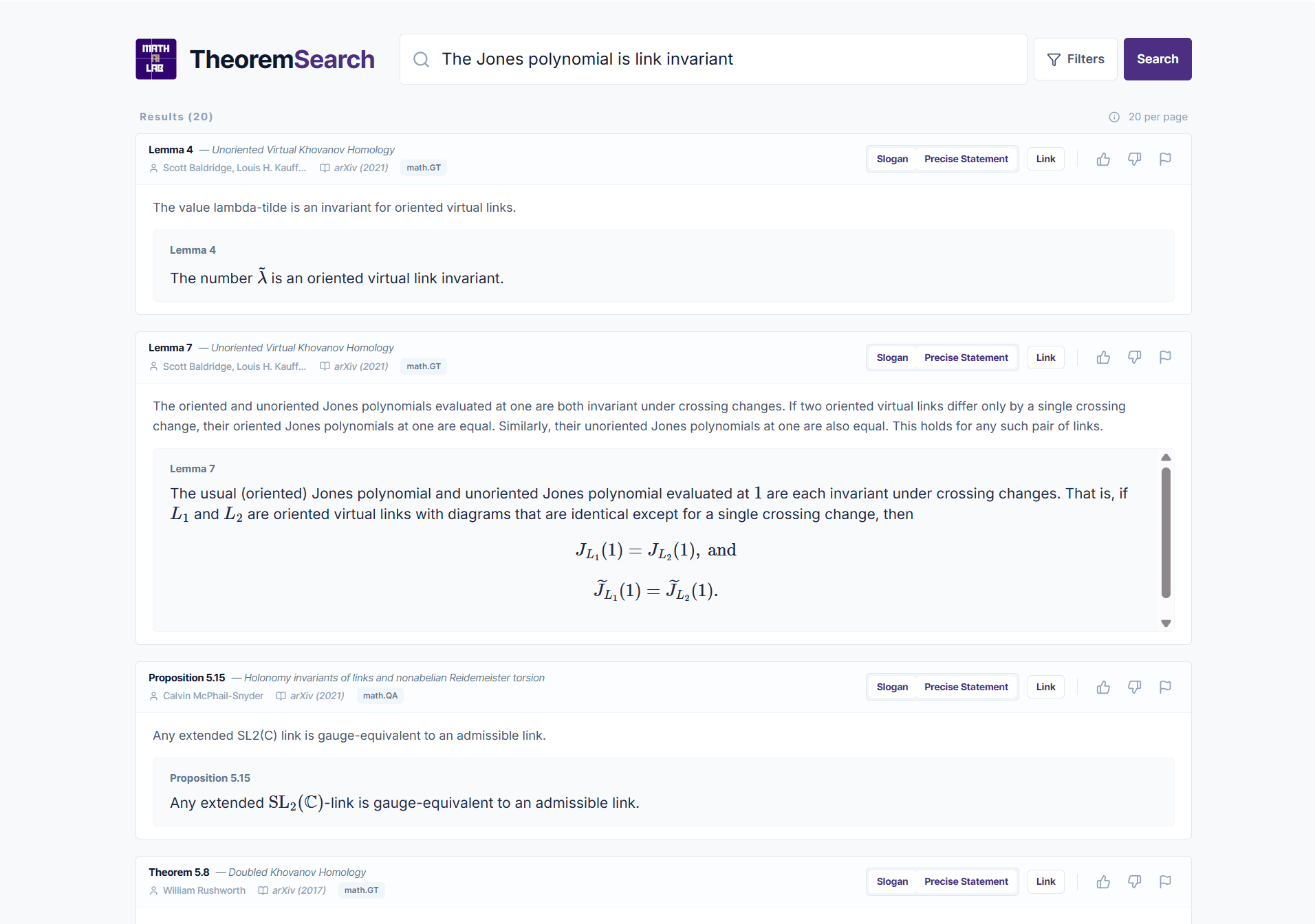
Mathematical knowledge is distributed across millions of papers. However, existing search tools only operate at the document level, and important results can be hard to surface in lesser-known sources. We want to democratize math by enabling search at the theorem level.
For mathematicians, a bottleneck in modern research is discovery; i.e., locating relevant lemmas or prior results already buried somewhere in the literature. Furthermore, sources like The Stacks Project are valuable repositories of branch-specific knowledge, but Google cannot reliably surface individual results, and any built-in search capabilities are largely limited to keywords and tags. Through documented case studies and user feedback, TheoremSearch is a reliable tool for theorem discovery.
For AI agents, we believe reliable autonomous mathematical discovery necessitates granular access to relevant literature. Many of the recent AI breakthroughs on Erdős problems turned out to be rediscoveries of results already in the literature. For example, 9/13 of DeepMind Aletheia’s meaningfully correct generated solutions were either classified as independent rediscoveries or identifications of results in existing literature. It is also true that LLMs often fabricate incorrect arguments. In our experiments, Claude answered a research-level algebraic geometry question incorrectly on its own, but correctly when given access to TheoremSearch as a RAG tool.
How It Works
- 1
Parse theorems. We extract over 9 million theorem statements from LaTeX sources across arXiv and seven other sources using a combination of plasTeX, TeX logging, and regex-based parsing.
- 2
Generate slogans. Each theorem is summarized into a concise natural-language description ("slogan") by DeepSeek V3 to convert formal LaTeX notation into searchable text.
- 3
Embed and index. Slogans are embedded using Qwen3-Embedding-8B and stored in a PostgreSQL database with pgvector, using an HNSW index with binary quantization for fast approximate nearest-neighbor search.
- 4
Retrieve. User queries are embedded with the same model. We retrieve the top-k theorems by Hamming distance, then re-rank by cosine similarity.
Overview
Retrieval Performance (Hit@10)
| MODEL | THM-LEVEL | PAPER-LEVEL |
|---|---|---|
| Google Search | — | 0.378 |
| ChatGPT 5.2 | 0.180 | — |
| Gemini 3 Pro | 0.252 | — |
| Ours | 0.432 | 0.505 |
Theorem-level = retrieval of exact theorem statements
Paper-level = retrieval of the correct paper containing the theorem
Data Sources
| SOURCE | THEOREMS |
|---|---|
| arXiv | 9,246,761 |
| ProofWiki | 23,871 |
| Stacks Project | 12,693 |
| Open Logic Project | 745 |
| CRing Project | 546 |
| Stacks and Moduli | 506 |
| HoTT Book | 382 |
| An Infinitely Large Napkin | 231 |
REST API
TheoremSearch provides a production REST API for semantic theorem search.
curl https://api.theoremsearch.com/search \
-H "Content-Type: application/json" \
-d '{"query": "smooth DM stack codimension one", "n_results": 5}'Returns theorem-level results with metadata and similarity scores. Full API reference →
MCP Tool
TheoremSearch is available as an MCP tool for AI agents via a single theorem_search tool.
https://api.theoremsearch.com/mcp